📊 Business Context
What is it about?
- RFM segmentation classifies customers according to their individual buying behavior.
- Each contact is scored based on 3 criteria:
- R = Recency of the last purchase.
- F = Frequency of purchases.
- M = Cumulative amount of purchases.
- For each criteria, the contact has a relative score raging from (low) 1 to 6 (high).
- For example, if a contact as R = 1, it means that the contact is part of the 1/6 of the customer database with the oldest last purchase date.
- Then, we combine F and M scorings into “FxM” in order to have a two-dimensions scoring on which segments are based.
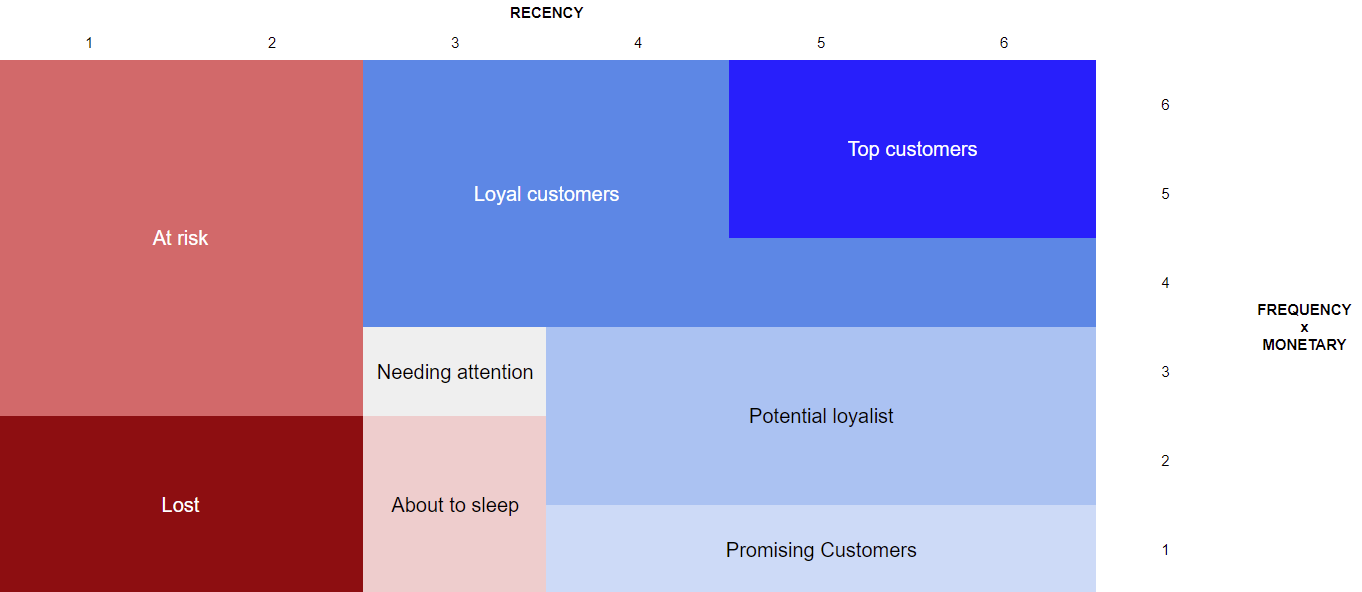
- For example, we can define the segment “Top customers becoming passive” with R IN {1,2} and FxM IN {5,6}.
- In theory, with a 2-dimensions scoring, having 6 potential values each, you can build up to 6 x 6 = 36 segments. But usually there is no point in having more than 10 segments.
- What does a RFM segmentation look like?
You can materialize your segmentation like this
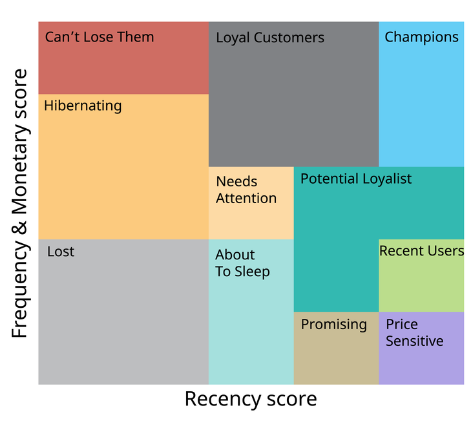
What are the main use cases?
- Understand and drive the business based on trends in RFM segments and their contribution to segments and their contribution to key performance indicators.
- Differentiate offer and personalization levels according to segment quality, to improve brand engagement while ensuring optimal ROI of actions
- Easily target the best customers for an operation or exclude those less likely to respond likely to respond.
What business impact can I expect?
- Impact on: Retention rate, Number of orders per customer.
- Level of impact: ⭐️⭐️️⭐️⭐️⭐️
↔️ Inputs & Outputs
Data input
You need a dataset made of Orders with at least the following attributes :
order_id: unique identifier of the transaction.
customer_id: unique identifier of the customer who made the purchase.
order_date: date at which the purchase was made.
order_amount: total amount that was spent by the customer for this order.
You will also need a Customers dataset with following attributes
customer_id: unique identifier of the customer who made the purchase.
User settings
The user can adjust the following settings according to his needs :
The number of values for each axis (R, F and M)
The number of segments based on the values of R and FxM
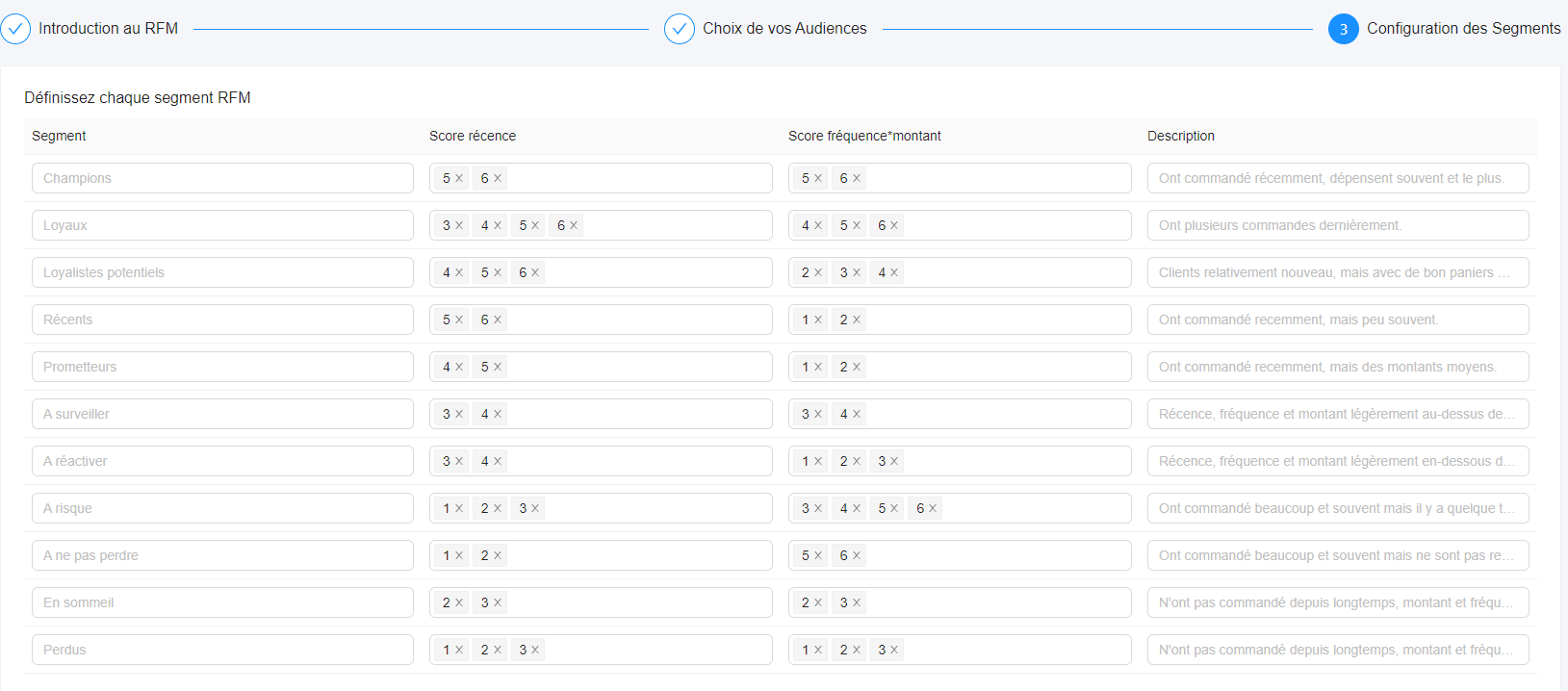
- The segment names depending on the number of segments.
Expected output
- The output of this recipe is a new Dataset containing a row for each of your contacts which made at least one purchase.
- In this Dataset, besides
contact_idyou will have 3 output columns : rfm_recency: this is the recency scoring of the contact, meaning the R value in RFM.rfm_frequency_monetary: this scoring covers both Frequency (F) and Monetary (M) of RFM.rfm_label: the segment label for the contact defined according to the values of R and FxM.
- You can then make a join between your new RFM Dataset and your existing Contacts Dataset to map your rfm_label for instance.
🖥️ Implementation in Octolis
1. Prepare your input data
Make sure that you have built an Dataset containing all your orders.
In case you have several order Sources (e.g. eShop & PoS) you need to group all sources into an orders master Dataset.
2. Apply the SQL Template “RFM”
- Create a new Dataset using SQL expert mode.
- Copy / past the following SQL template.
- After pasting the template, make sure to replace the column names in the query with the names of your actual columns.
contact_masterid: column in your orders Dataset that contains the unique identifier of the contact who made the order.created_at: column that contains the date of each order.total_amount: column that contains the amont spent by the customer for each order.category: column that contains the type of each order (usually in Octolis : online / offline / abandoned_cart).completed: column that indicates if the order has been completed or not (sometimes usefull for online orders that can be stored in DB before being paid).
- Add your RFM Dataset as a source of your Contacts Dataset, map the needed fields to import them into your Contacts Dataset.
sql/* RFM Segmentation SQL Template */ WITH A AS ( SELECT "contact_masterid", max("created_at"::timestamp) AS "last_order_date", count(*) AS "count_order", avg("total_amount"::float) AS "avg_amount" FROM {{ ref("name of orders' Audience") }} WHERE "contact_masterid" IS NOT NULL /* optional filters depending on your dataset */ AND "total_amount" > 0 AND "category" <> 'abandoned_cart' AND "completed" IS TRUE GROUP BY "contact_masterid" ), B AS ( SELECT "contact_masterid", ntile(6) OVER (ORDER BY "last_order_date") AS "rfm_recency", ntile(6) OVER (ORDER BY "count_order") AS "rfm_frequency", ntile(6) OVER (ORDER BY "avg_amount") AS "rfm_monetary" from A ), C AS ( SELECT "contact_masterid", "rfm_recency", ntile(6) OVER (ORDER BY "rfm_frequency" * "rfm_monetary") AS "rfm_frequency_monetary" FROM B ), D AS ( SELECT "contact_masterid", "rfm_recency", "rfm_frequency_monetary", (CASE WHEN "rfm_recency" IN (5, 6) AND "rfm_frequency_monetary" IN (5, 6) THEN 'Top Customers' WHEN "rfm_recency" IN (3, 4, 5, 6) AND "rfm_frequency_monetary" IN (4, 5, 6) THEN 'Loyal Customers' WHEN "rfm_recency"IN (4, 5, 6) AND "rfm_frequency_monetary" IN (2, 3) THEN 'Potential Loyalist' WHEN "rfm_recency" IN (4, 5, 6) AND "rfm_frequency_monetary" IN (1) THEN 'Promising Customers' WHEN "rfm_recency" IN (3) AND "rfm_frequency_monetary" IN (3) THEN 'Needing Attention' WHEN "rfm_recency" IN (3) AND "rfm_frequency_monetary" IN (1, 2) THEN 'About To Sleep' WHEN "rfm_recency" IN (1, 2) AND "rfm_frequency_monetary" IN (3, 4, 5, 6) THEN 'At risk' WHEN "rfm_recency" IN (1, 2) AND "rfm_frequency_monetary" IN (1, 2) THEN 'Lost' ELSE NULL END) AS "rfm_label" from C ) SELECT * FROM D;
Visualization of the output of the above query