
To set up your Octolis account in the most efficient way possible, it’s important to carefully design the organization of your datasets. With a clear architecture designed, the setup will be quicker, and it’s gonna be easier to make it evolve.
Understand how datasets work and interact
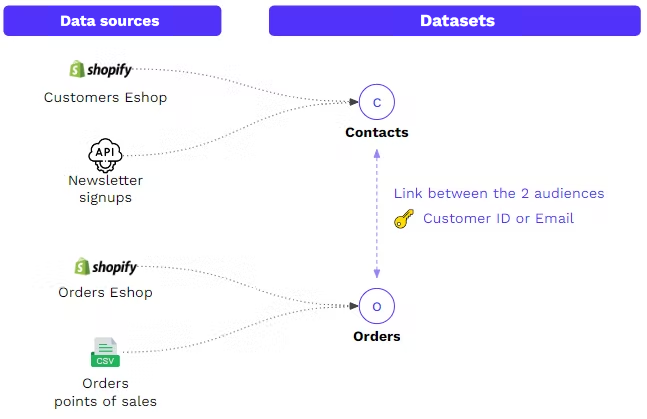
Sources files feed Datasets
A Dataset is a combination of several data sources, on which you could apply transformation rules (data prep, scoring, etc.).
For example, you could create datasets like:
- Master Contacts: Combine all contacts from different sources
- Master Orders: Combine several sources of orders
- Products Catalog, Consents history, Email interactions, etc.
Datasets can be built from your raw data sources, or from another dataset.
You can create an dataset with the no-code builder or in SQL.
Datasets can be linked
Once a dataset is created, you can join it with one or several other datasets. The main purpose is to be able to add computed fields based on the columns of another dataset.
For example, I can join my “Contacts” and my “Orders” datasets. This allows me to create new columns for each contact based on “Orders” columns, for example, the count of orders, the sum of orders amount, the average of orders from a specific category, etc.
For now, you manage the link between datasets at each dataset level. For example, in the dataset “Contacts”, I can join it with “Orders” to compute the number of orders per contact. If I open then the dataset “Orders”, there will be no “join” already defined. From the Orders dataset, I can join it (again) with the dataset “Contacts”, to add the customer name to each order for example.
How to design your datasets organization
Principle: 1 dataset for each business entity
Business entities could be Contacts, Orders, Products, Contracts, etc.
The idea is to have a “Master” dataset for each business entity. If never you need to create several datasets Contacts, you should have one “Contacts Master” dataset.
This principle has two implications.
- Split information related to different entities in several datasets.
For example, you have a source file “Contacts” with columns for Company name, Company address. The best practice is to consider “Companies” as a business entity, and to create a separate dataset “Companies”. By doing so, you will be able to create a create sync pipeline from the “Companies” dataset, and compute columns like the number of contacts for each company.
- Try not to create several datasets for the same business entity
You can connect different data sources to the same dataset. For example, a dataset “Contacts” could be fed at the same time by a Shopify connector, by a CSV file dropped every day in an FTP server, and by some API queries. Even if each data source has a different data model, you will be able to merge them into the same dataset.
In practice, there are some situations that lead to having several datasets for the same business entity. For example, when you need some advanced data preparation for one source file, it may be easier to use a SQL dataset. So you could have one SQL-based dataset “Contacts - Source A”, in addition to a no code built dataset “Contacts - Source B + C”. You will merge them into a “Master - Contacts” dataset. We recommend you use the prefix “Master -” (or something similar) to identify easily the master datasets.
When do you need to create more datasets?
Use SQL builder + no code builder
As said just above, if you need advanced data preparation in SQL for one specific source file, it may be useful to create one or more SQL datasets for specific source files, then merge them.
To split information related to several business entities
It’s the case of the source file containing information related to contacts and companies. In this case, you will need to create several datasets. It could be done by creating several no-code datasets based on the same data source and just deleting some columns or using SQL datasets that split the file into several datasets.
To send a custom table to some destination
When you configure a sync pipeline toward a destination, you start from a dataset to which you can apply some basic filters. There are often use cases for which you need some specific data preparation transformation on some dataset. In this case, you will create a dataset “on top” of the first one. For example, it could be a dataset “Export - Contacts - For my ERP”, that is based on the “Master - Contacts” dataset, on which you have applied some data prep to fit the requirements of the destination “My ERP”. Same logic as the “Master -” prefix, it could be useful to use the prefix “Export -” in the name of this type of dataset.
To create a dataset of scores
In the “No code” dataset builder, you can add quite simple computed fields based on a joined dataset. You can also add a SQL recipe but use only the columns of this dataset. For advanced scores, you may need to create a SQL dataset that will be able to use all the datasets. It happens often for the Contacts dataset, we compute most of the aggregates (=scores) in a SQL dataset “Contacts - Agg” which is joined to the “Master - Contacts” dataset.
To create a data-logging dataset of metrics
You could create a dataset using metrics only. For example “Daily Customer stats”, a dataset containing a line for each day with columns like “Nb customers”, “Nb active customers”, etc.
Zoom on some architectural examples
Example #1 - Retail company with Splio as the main destination
Let’s take the example of a retail company who have both an e-commerce website and a point of sale. This company is using the marketing CRM solution Splio as the main destination.
Macro level - Datasets organization
In this case, the main complexity comes from the fact that we need to merge Orders and Orders items to send them to the destination “Splio API”.
Data level - Datasets data models
Ideally, you should take the time to detail each dataset data model, and the link between datasets before configuring anything. The more precise your vision of the target data model, the quicker the configuration will be. This job can be done in Excel or with a database design tool like drawsql.app or dbdiagram.io.