
For advanced needs (like scoring design), Octolis has a feature to create SQL Datasets.
In this article you will find :
- A step by step guide to build basic SQL Datasets
- Advanced guidelines on templating and queries optimization
1. Building basic SQL Datasets
Step 1 - Starting a new SQL Dataset
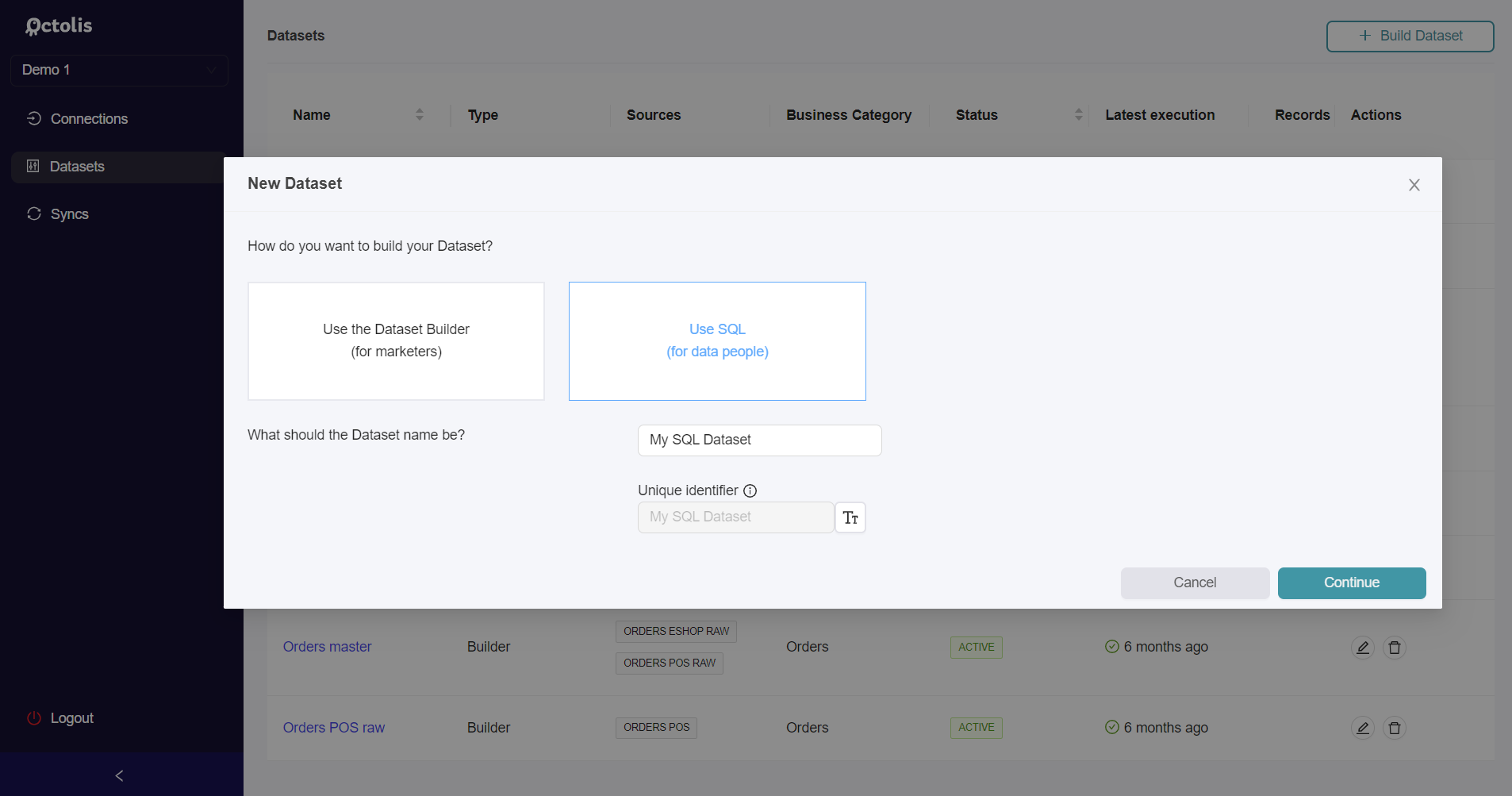
In the Datasets section, click the upper right button Build Dataset.
Select the Use SQL option in modal, give a name to your Dataset and click Continue
Step 2 - Adding Sources
Your SQL Dataset can be built upon one or several data Sources.
For example, you can use an existing Dataset, a PG SQL table or an SFTP file.
To add a source to your SQL Dataset, click the Add Source data button.
When you add a Source, each time there is modification in your Source, the entire SQL Dataset will be recalculated automatically.
In some very specific cases, you might need to change this behaviour, please read : Decorrelating Source updates and Dataset updates
Add Source wizard
This opens a 3 steps wizard.
You move to next step by clicking the Continue button in the upper right corner.
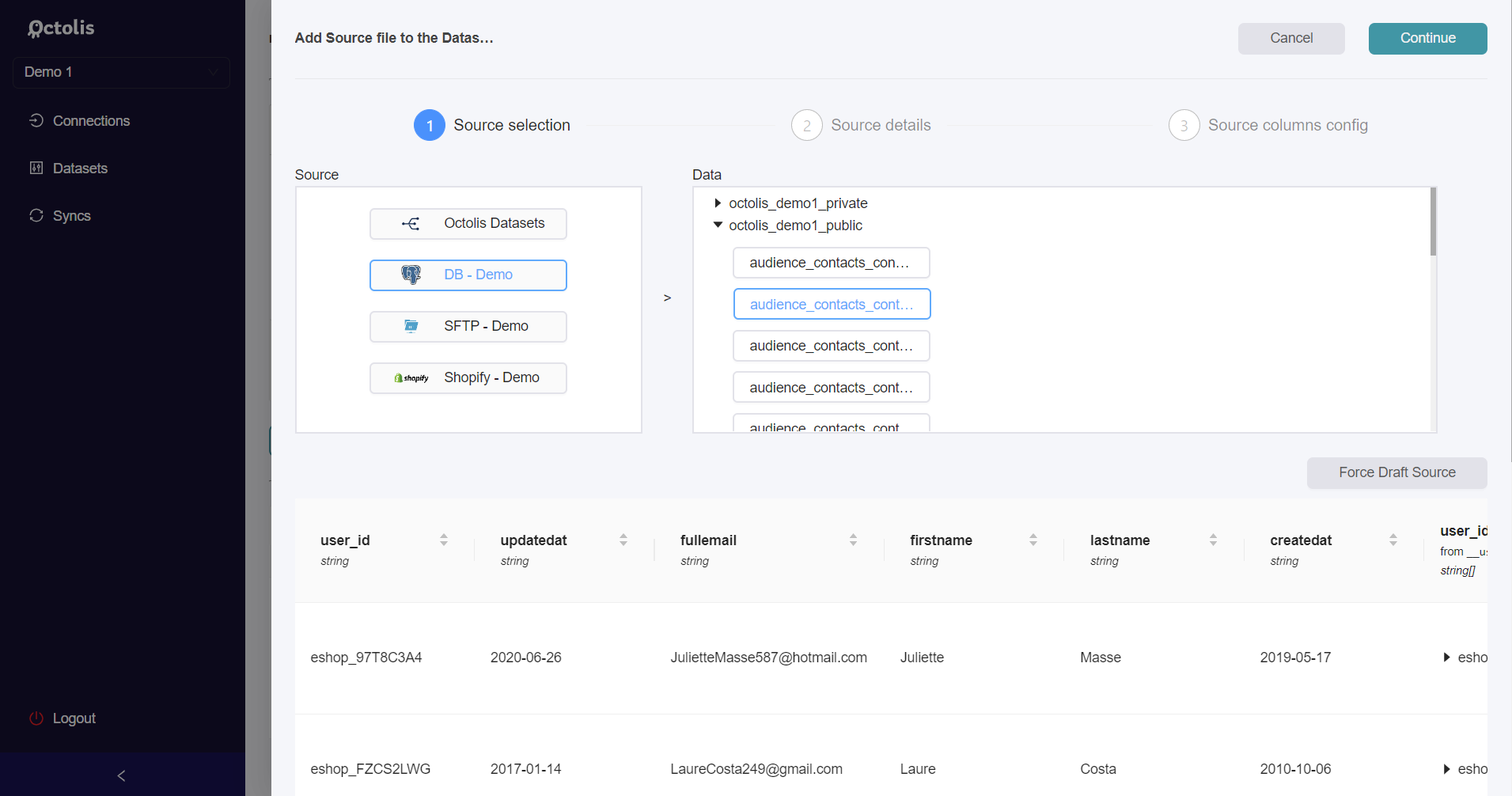
At step 1 you have to pick a source type (based on your available Connections) and then select an item in the Data block. Then click the Continue button.
At steps 2 and 3, you might have to provide additional details about the Source, depending on the type of Source you selected.
Once you’re done, click again the continue Continue button and you’ll land back on the initial screen with a new item in Source data panel (on the left) and a draft SQL query in the central editor.
You can repeat this whole step several times to add other sources to your SQL Dataset if you need to manipulate data from various origins.
Step 3 - Writing a query
Basic query syntax
First, take a look at the query template created by default in the editor.
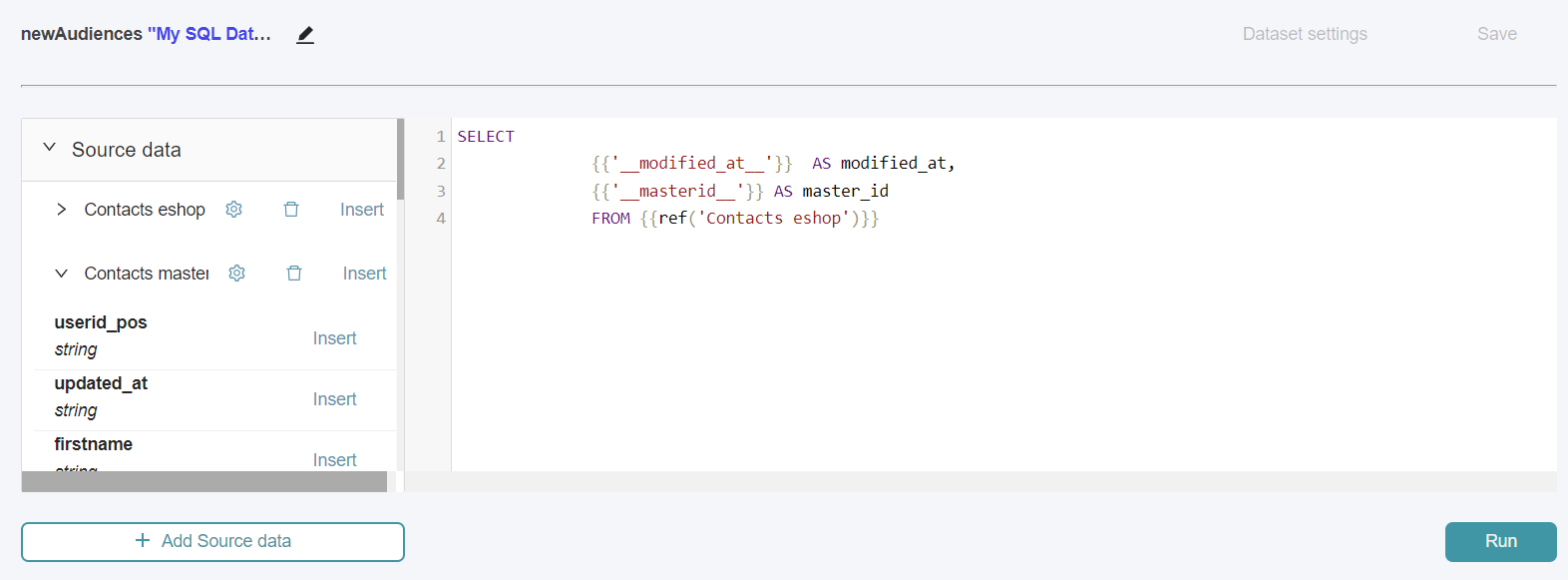
The
{{ ref("Source name") }} syntax :It is the correct way to refer to a Source in your query. It should be used instead of using a table name even if your source is a DB table, except for advanced cases.
The
{{'field_name'}} syntax :It is completly optional, you can use the name of the field instead.
sqlSELECT {{'userid_pos'}} AS "userid" FROM {{ref('Contacts master')}};
Is equivalent to:
sqlSELECT userid_pos AS "userid" FROM {{ref('Contacts master')}};
Source data panel
The Source data panel indicates the Sources already added for your Dataset.
It displays the names you can use in the
{{ ref("Source name") }} syntax.Click on a Source name in this panel to show the list of all available fields you can use in your query (with or without the
{{'field_name'}} syntax). Drafting your query
Now is the time to write a first draft of your query! You don’t need to make it perfect right now, as you will be able to fine tune it later.
But your draft query should at least be valid, don’t end with a semi-column
; but with a SELECT that outputs the following required columns with their right names :- the column(s) to use a deduplication key for the Dataset,
- the column that indicates the last modification date of each record.
If your not sure about what you are doing just write a simple SELECT turning some data of one of your sources into a the desired column names for the required fields.
Click the Run button to enable access to Dataset settings.
Then click the Dataset settings button in the upper right corner.
NB : Your results won’t be displayed at the first run because you first need to choose your Dataset’s settings.
Step 4 - Defining your settings
Please not that you won’t be able to define your settings if your query is not valid (or ends up with a semi-column).
- Please fill all the required fields indicated with a red star :
- business category
- last modification column
- deduplication key columns
For the last modification column, most of the time in SQL Datasets you should use an
updated_at column equal to now() or current_date, or the __modified_at__ system column from another Dataset.- Optional columns can be left blank / deactivated (ask support for advanced cases) :
- preserved values
- immutable columns
- data API activation
- For SQL mode, leave default option (a SELECT query) unless you know what you are doing.
Once everything is set, save your settings with the Save button.
Step 5 - Rendering your query
After saving the settings, you need to click again the Run button before being able to finally Save your entire Dataset.
Once you’ve clicked the Run button again, you will finally get a first preview of your query’s results in the lower part of the screen.
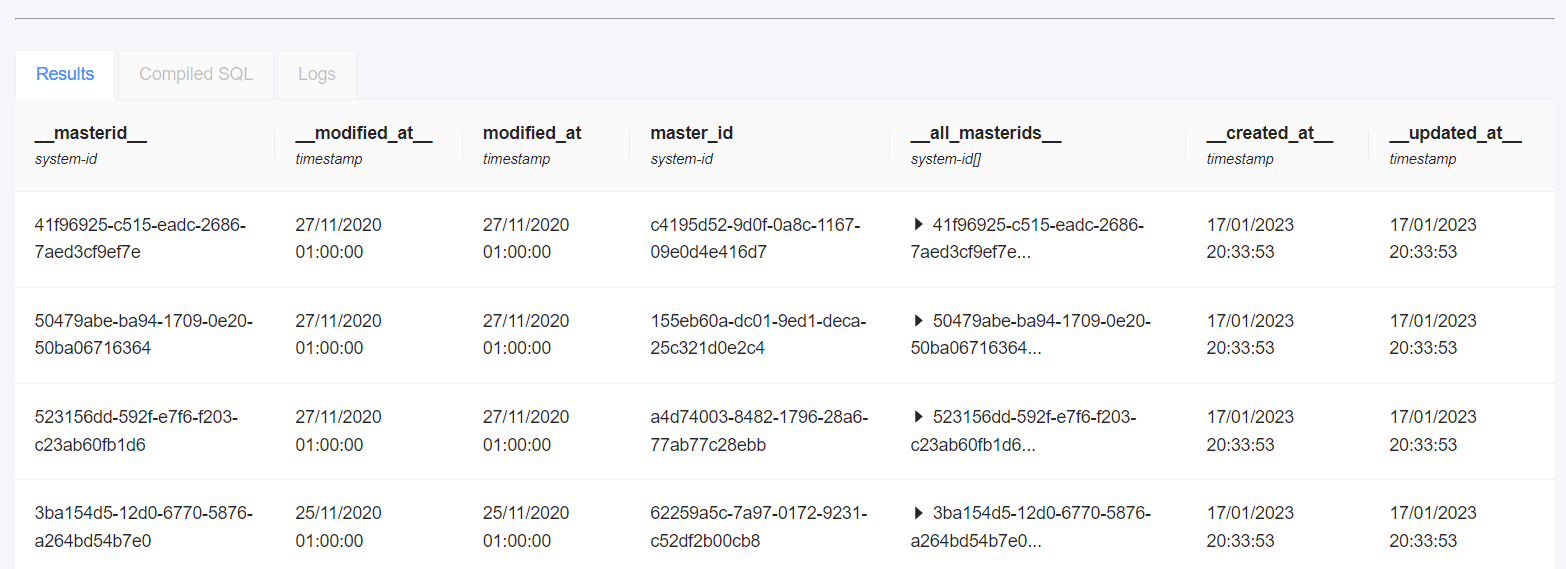
Step 6 - Iterating on your query
Now that you’ve been able to get a first render, you can fine tune your query : add sources, add CTEs, etc. You can still edit settings also if needed.
You’re done? Now is the time to finally click on the Save button to Save the entire Dataset.
Please rember that each time you make some modifications (in the query or the settings) you have to click the Run button before saving your Dataset.
2. Advanced guidelines
Using Nunjucks templating language
This means that all the templating syntax from Jinja is available inside of Octolis SQL Datasets to generate powerful queries e.g. if/else conditional syntax, for loops...
Octolis also extends this templating syntax with some functions often inspired by DBT (which also uses Jinja).
Especially, please note the
{{ ref("Source name") }} syntax that should be used instead of directly referring to the Source table name.This way, users don't have to know the actual table name of the Source to write queries.
Decorrelating Source updates and Dataset updates
In some advanced cases, you might want your SQL Dataset not to be recalculated when each Source is updated.
For exemple, let’s say you build a SQL Dataset A that uses Datatset B and C as sources. If Dataset B uses C as a source himself, he will be updated each time there is a modification in C.
So instead of rebuilding A each time there is a modification in B and each time there is a modification in C, we can only rebuild A once B is updated (which occurs after a modification of C).
In this case, we will have to do two things :
- remove Dataset C from Sources in the left panel, by clicking on the trash icon next to it’s name,
- update the SQL query to refer to Dataset C using
schema_name.table_nameof_dataset_binstead of the ref syntax{{ ref("Dataset B") }}
This requires to know the names of the schemas and tables in the database hosting Octolis. If you feel like you need this info, please get in touch with support.
Optimizing your query depending on the execution context
The $scope variable of a SQL Dataset execution
$scope='standalone':
The SQL query runs in the context of either an
entireAudience or a sql execution.
All data from all Sources is fetched, and the SQL query runs againts them.
All you need to do is using the usual SELECT ... FROM {{ ref("Source name") }} syntax.$scope='increment':
The SQL query runs in the context of a
connectionSource, syncSource, or webhookSource execution.
The incremental data of only one Source enters the SQL Dataset.
Here it becomes interesting as this is THE way of adapting/improving your query.
Why run a query against all data of all Sources when you know there are only a few new incremental changes?The $origin_name variable and {{ ref($origin) }} table of a SQL Dataseet execution
$origin_nameis a variable equal to name of the Source that emitted the incremental changes.
{{ ref($origin) }}is the table containing the incremental changes.
This is only applicable when
$scope='increment'A first example
Let's say you compute some orders aggregates in a SQL Dataset. A usual query would look like the following:
sqlSELECT orders.contact_masterid, orders.total_amount, orders.__modified_at__ as modified_at FROM {{ ref("Orders source") }} orders GROUP BY contact_masterid
Whatever the kind of execution, this will always work, as it always fetches all data from the orders Source and computes aggregates based on it.
Now let's take a step back. This is not efficient at all in the case of a
connectionSource execution.
Instead of only processing the incremental changes, it will work against all the Source data.Let's adapt the query:
sqlSELECT orders.contact_masterid, orders.total_amount, orders.__modified_at__ as modified_at {% if $scope === "increment" %} FROM {{ ref($origin) }} {% else %} FROM {{ ref("Orders source") }} {% endif %} GROUP BY contact_masterid
Which is of course equivalent to:
sqlSELECT orders.contact_masterid, orders.total_amount, orders.__modified_at__ as modified_at FROM {% if $scope === "increment" %}{{ ref($origin) }}{% else %}{{ ref("Orders source") }}{% endif %} GROUP BY contact_masterid
This is already way better.
This simple syntax only works because there is only one source, otherwise, you would have to use:
{% if $scope === "increment" and $origin_name === 'Contacts source' %} instead of only
{% if $scope === "increment" %}.A second example
Now let's say you have two contacts and order Sources that can trigger your SQL Dataset.
A basic query would look like the following:
sqlSELECT contacts.__masterid__::text as contact_masterid, contacts.first_name, contacts.last_name, sum(orders.total_amount) as ltv, greatest(contacts.__modified_at__, max(orders.__modified_at__)) as modified_at FROM {{ ref('Contacts source') }} contacts LEFT JOIN {{ ref('Orders source') }} orders ON contacts.__masterid__::text = orders.contact_masterid;
Now let's optimize it so that we don't compute aggregates for all contacts again when there are only a few incremental changes coming from the contacts Source:
sqlSELECT contacts.__masterid__::text as contact_masterid, contacts.first_name, contacts.last_name, sum(orders.total_amount) as ltv, greatest(contacts.__modified_at__, max(orders.__modified_at__)) as modified_at {% if $scope === "increment" and $origin_name === 'Contacts source' %} FROM {{ ref($origin) }} contacts {% else %} FROM {{ ref("Orders source") }} {% endif %} LEFT JOIN {{ ref('Orders source') }} orders ON contacts.__masterid__::text = orders.contact_masterid;
Now let's optimize it also for the case when there are incremental changes coming from the orders Source:
sqlSELECT contacts.__masterid__::text as contact_masterid, contacts.first_name, contacts.last_name, sum(orders.total_amount) as ltv, greatest(contacts.__modified_at__, max(orders.__modified_at__)) as modified_at FROM {% if $scope === "increment" and $origin_name === 'Contacts source' %}{{ ref($origin) }}{% else %}{{ ref("Contacts source") }}{% endif %} contacts LEFT JOIN {% if $scope === "increment" and $origin_name === 'Orders source' %}{{ ref($origin) }}{% else %}{{ ref('Orders source') }}{% endif %} orders ON contacts.__masterid__::text = orders.contact_masterid {% if $scope === "increment" and $origin_name === 'Orders source' %} WHERE contacts.__masterid__::text IN (SELECT origin.contact_masterid FROM {{ ref($origin) }} AS origin) {% endif %}
And that's it! This way your query will always run in an optimized way over the mimimum required number of records.
This is how Octolis works internally in "builder" Datasets to ensure performance.
Warning
When you read this you maybe thought it makes sense to implement those optimizations into each and every SQL Dataset. But this does not always make sense...
Let's take the RFM segment for instance: it should always be computed again each time there is a new order or a new contact.