
1. Understand the different ways of preparing your data
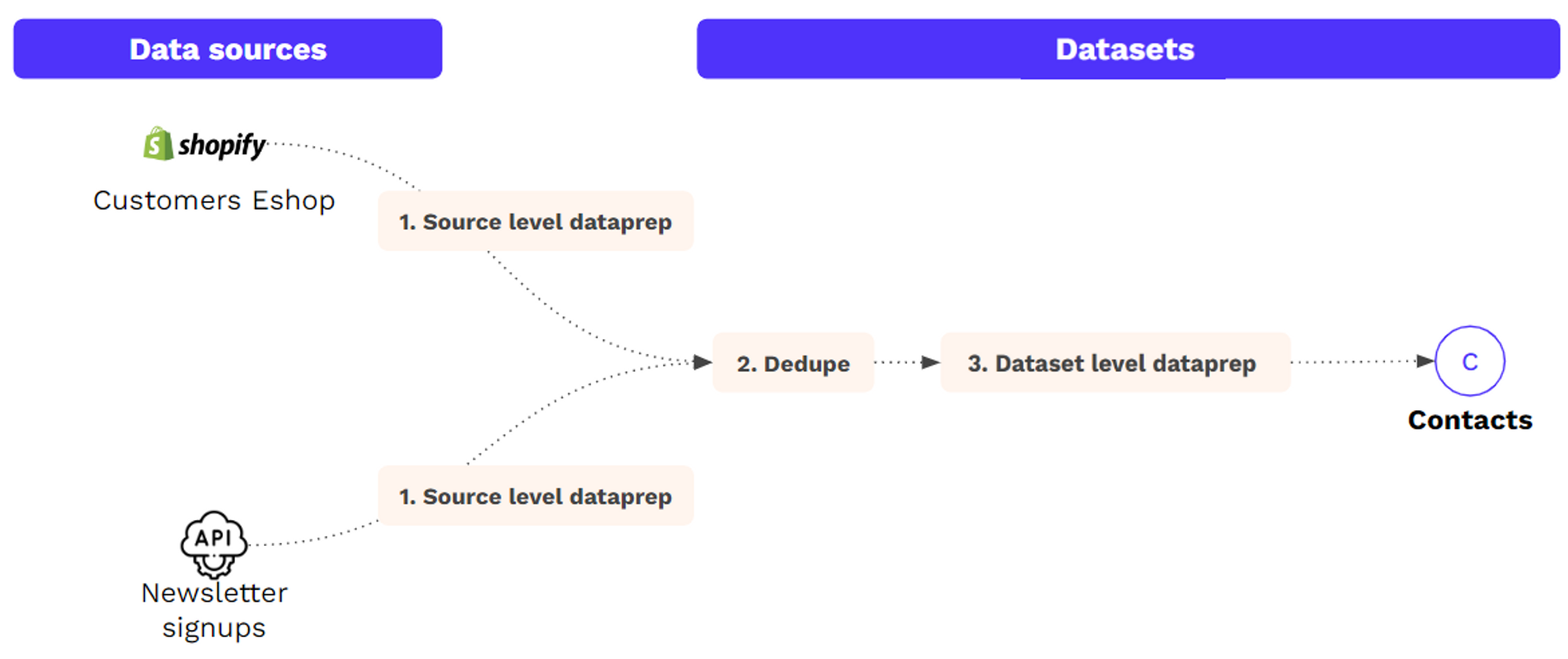
There are several ways to prepare your data sources, when you create a new dataset, you choose one or several sources that feed this dataset.
Sources are then deduped/merged to form a unified table (=the dataset).
Most data preparation should be applied at the dataset level after sources are unified, however, you can also apply some data preparation at the source level, before dedupe, as seen in the previous tutorial “Create a no-code dataset”.
Finally, some advanced use cases may happen to use some custom SQL dataset for data preparation.
2. Source-level transformations
When you add a new source, it’s possible to add some preparation rules for each column in the mapping step.
The main purpose of source-level data preparation is to prepare columns used for dedupe.
Because the dedupe is processed just after importing the sources, it could be necessary to normalize the columns used in the dedupe at the first step, right after importing the sources files.
For example, if you want to dedupe your contacts based on Email x Phone number, you will need to normalize these 2 columns to be sure that “john.doe@gmail.com x 0660036339” matches with “JOHN.doe@gmail.com x +33660036339”.
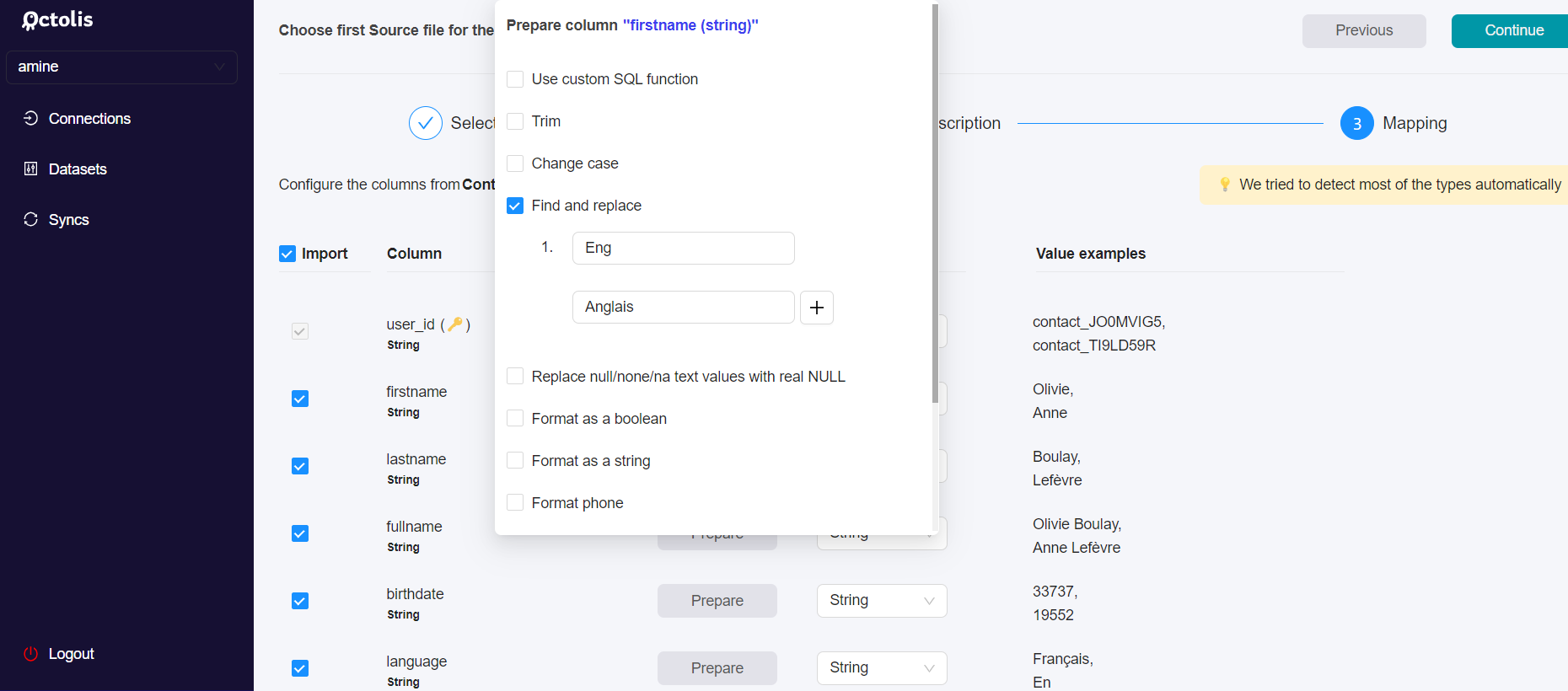
Most data prep options available at this step are quite easy to understand. For each column, you can choose to put the column value in “lowercase” or to apply a “Find & Replace “ function.
In the end, when you click on “Continue”, the fields will be mapped with your dataset, and you will be able to see a preview and save it.
3. Dataset-level transformations
1 - Recommendations
We highly recommend:
- Using transformations at the source level for the columns used at the deduplication level.
- Source 1: the “phone_number” column is formatted as “+336********”
- Source 2: the “phone_number” column is formatted as “06********”
Example: I want to merge one source with another using the column “phone_number” as the deduplication key between the two sources.
I have to add a preparation step to at least one of my sources in order to normalize the “phone_number” columns and don’t end up with duplicates after merging the sources.
- Using transformations at the dataset level for other fields.
As we saw it, it is also possible to do some transformations during the creation of the dataset, before the dedupe step.
Sometimes it makes sense to apply transformations on the Source level, especially on columns used for dedupe.
2 - How does data preparation work?
In your dataset view, the right sidebar lists all the data preparation recipes applied to your dataset. If you click on "Add Preparation", you will see the list of all recipes available, and you can quickly add a new one.
The different data preparation tools are visible on the right-hand banner of the screen below:
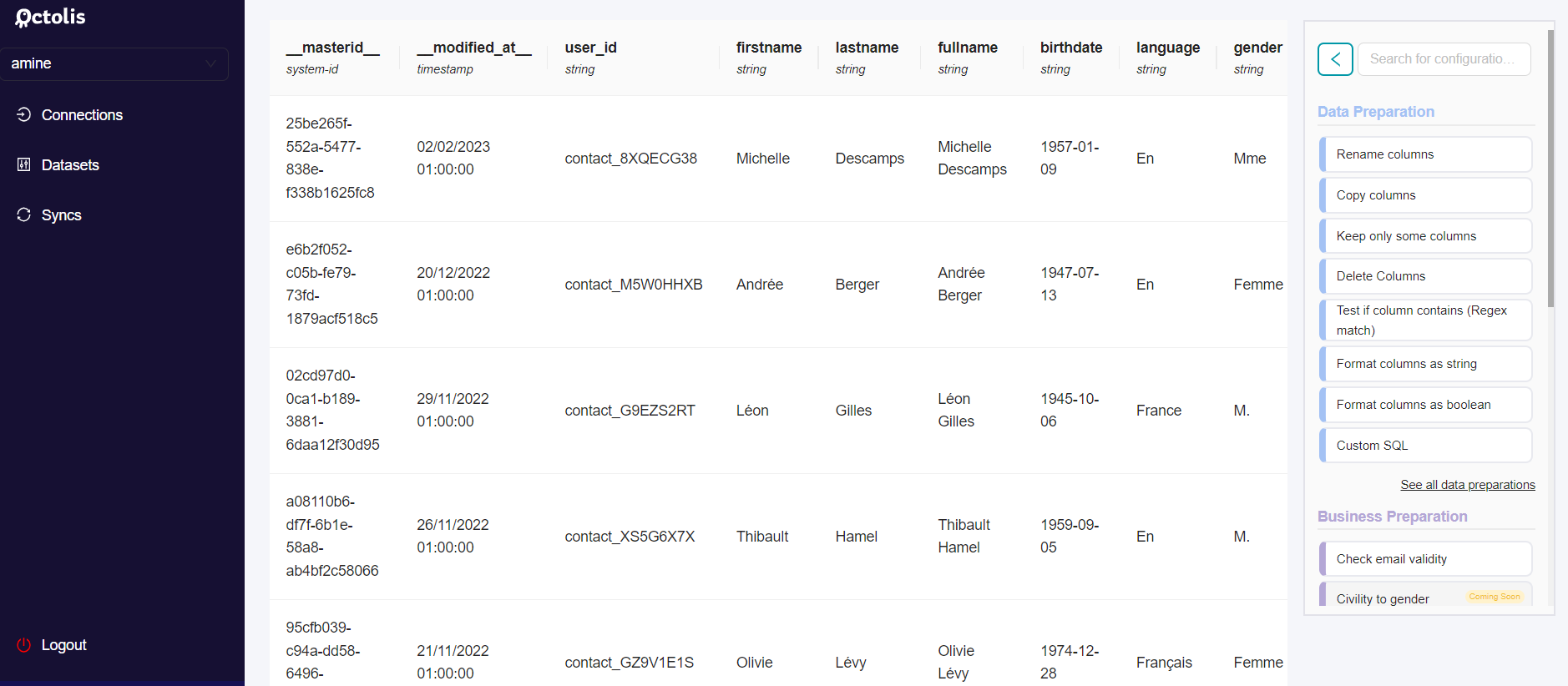
All these preparations are processed each time there is a record created or updated in the source feeding the dataset, in almost real-time.
- These preparations are processed following the position of the item in the sidebar.
- There are some "data preparation" tools created by default to process the merge of the various sources and the dedupe process.
When you add a new preparation, it will be added at the end of the sidebar. You can click on an existing preparation to modify or delete it. For now, you cannot change easily the position of the preparations in the listing, but it will be possible soon.
Please don't forget to click on "Save" after modifying the data preparation recipes. After clicking on Save, the dataset will be rebuilt.
3 - What are all the data preparations available?
List of all no code data preparations available :
4 - Zoom on SQL functions
There is one option that is more advanced: Applying a custom SQL function.
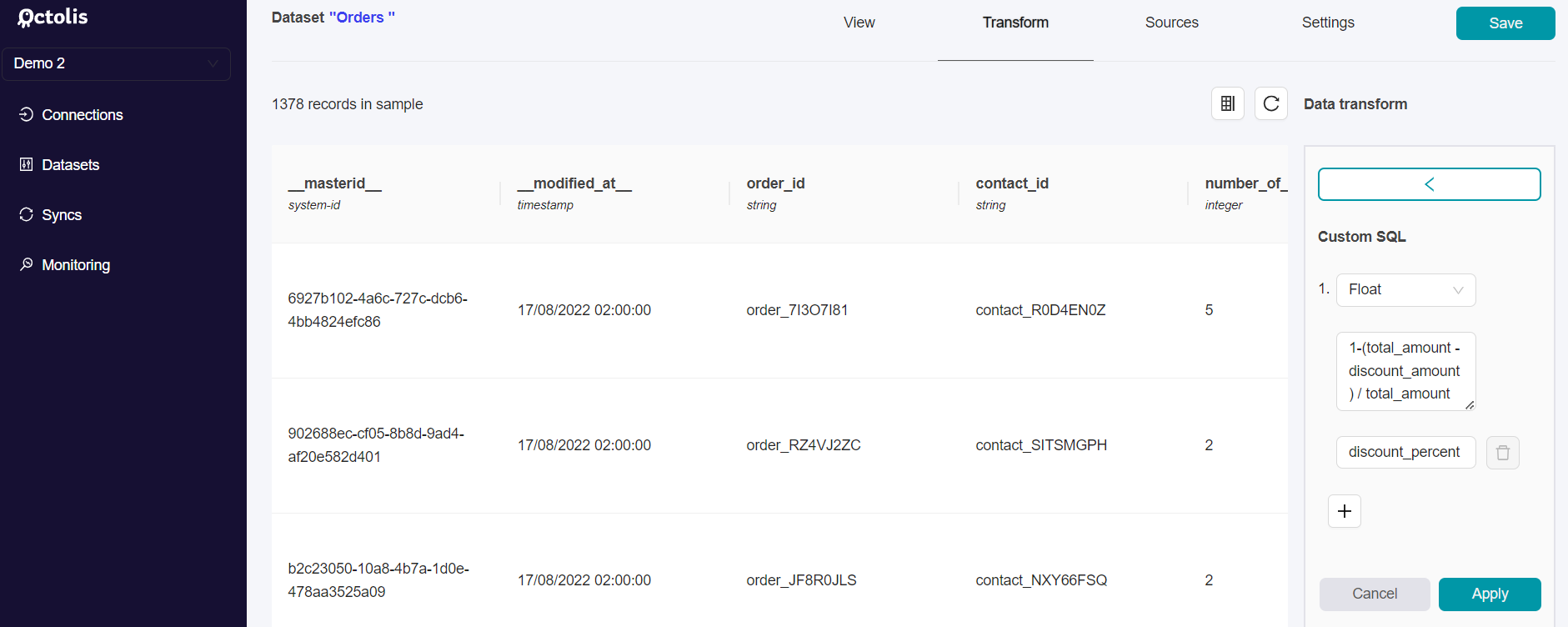
As some advanced data preparation could be difficult or almost impossible to do within the “no code” dataset builder, it is also possible to build a full SQL dataset to have more flexibility in preparing your data sources.
For example, if I want to create a dataset “Consents” based on the columns “Optin Email” / “Optin SMS” of my contacts, it implies transforming columns as new lines, there is no way to do it using the “no code” data preparations.